
Через 10 лет мир перейдет в новую эпоху — эпоху больших данных. Вместо виджета погоды на экране смартфона, он сам подскажет вам, что лучше одеть. За завтраком телефон покажет дорогу, по которой вы быстрее доберетесь до работы и когда нужно будет выехать.
Под влиянием Big Data изменится все, чего бы не коснулся человек. Разберемся, что это такое, а также рассмотрим реальное применение и перспективы технологии.
Навигация по материалу:
- 1 Что такое Big data?
- 2 Как работает технология Big-Data?
- 2.1 Машинное обучение
- 2.2 Анализ настроений
- 2.3 Анализ социальных сетей
- 2.4 Изучение правил ассоциации
- 2.5 Анализ дерева классификации
- 2.6 Генетические алгоритмы
- 2.7 Регрессионный анализ
- 3 Реальное применение Big Data
- 4 Перспективы использования Биг Дата
- 5 Рынок Big data в России
Содержание
- Что такое Big data?
- Как работает технология Big-Data?
- Реальное применение Big Data
- Перспективы использования Биг Дата
- Рынок Big data в России
- Big Data
- Data science
- Машинное обучение
- Data mining
- Облака
- Суперкомпьютер
- Интернет вещей
- Экскурс в историю и статистику
- Как работает технология big data?
- Для чего используют?
- Методики анализа и обработки
- Большие данные в бизнесе и маркетинге
- Перспективы развития
- Резюме
- Примеры Big Data
- Классификация Big Data
- Характеристики Big Data
- Big data: применение и возможности
- Решения на основе Big data: «Сбербанк», «Билайн» и другие компании
- Big data в мире
- Big data в банках
- Big data в бизнесе
- Big data в маркетинге
- Биг дата изменит мир?
Что такое Big data?
Большие данные — технология обработки информации, которая превосходит сотни терабайт и со временем растет в геометрической прогрессии.
Такие данные настолько велики и сложны, что ни один из традиционных инструментов управления данными не может их хранить или эффективно обрабатывать. Проанализировать этот объем человек не способен. Для этого разработаны специальные алгоритмы, которые после анализа больших данных дают человеку понятные результаты.
В Big Data входят петабайты (1024 терабайта) или эксабайты (1024 петабайта) информации, из которых состоят миллиарды или триллионы записей миллионов людей и все из разных источников (Интернет, продажи, контакт-центр, социальные сети, мобильные устройства). Как правило, информация слабо структурирована и часто неполная и недоступная.
Как работает технология Big-Data?
Пользователи социальной сети Facebook загружают фото, видео и выполняют действия каждый день на сотни терабайт. Сколько бы человек не участвовало в разработке, они не справятся с постоянным потоком информации. Чтобы дальше развивать сервис и делать сайты комфортнее — внедрять умные рекомендации контента, показывать актуальную для пользователя рекламу, сотни тысяч терабайт пропускают через алгоритм и получают структурированную и понятную информацию.
Сравнивая огромный объем информации, в нем находят взаимосвязи. Эти взаимосвязи с определенной вероятностью могут предсказать будущее. Находить и анализировать человеку помогает искусственный интеллект.
Нейросеть сканирует тысячи фотографий, видео, комментариев — те самые сотни терабайт больших данных и выдает результат: сколько довольных покупателей уходит из магазина, будет ли в ближайшие часы пробка на дороге, какие обсуждения популярны в социальной сети и многое другое.
Методы работы с большими данными:
- Машинное обучение
- Анализ настроений
- Анализ социальной сети
- Ассоциация правил обучения
- Анализ дерева классификации
- Генетические алгоритмы
- Регрессионный анализ
Вы просматриваете ленту новостей, лайкаете посты в Instagram, а алгоритм изучает ваш контент и рекомендует похожий. Искусственный интеллект учится без явного программирования и сфокусирован на прогнозировании на основе известных свойств, извлеченных из наборов «обучающих данных».
Машинное обучение помогает:
- Различать спам и не спам в электронной почте
- Изучать пользовательские предпочтения и давать рекомендации
- Определять лучший контент для привлечения потенциальных клиентов
- Определять вероятность выигрыша дела и устанавливать юридические тарифы
Анализ настроений
Анализ настроений помогает:
- Улучшать обслуживание в гостиничной сети, анализируя комментарии гостей
- Настраивать стимулы и услуги для удовлетворения потребностей клиента
- Определить по мнениям в социальной сети о чем думают клиенты.
Анализ социальных сетей
Анализ социальных сетей впервые использовали в телекоммуникационной отрасли. Метод применяется социологами для анализа отношений между людьми во многих областях и коммерческой деятельности.
Этот анализ используют чтобы:
- Увидеть, как люди из разных групп населения формируют связи с посторонними лицами
- Выяснить важность и влияние конкретного человека в группе
- Найти минимальное количество прямых связей для соединения двух людей
- Понять социальную структуру клиентской базы
Изучение правил ассоциации
Люди, которые не покупают алкоголь, берут соки чаще, чем любители горячительных напитков?
Изучение правил ассоциации — метод обнаружения интересных взаимосвязей между переменными в больших базах данных. Впервые его использовали крупные сети супермаркетов для обнаружения интересных связей между продуктами, используя информацию из систем торговых точек супермаркетов (POS).
С помощью правил ассоциации:
- Размещают продукты в большей близости друг к другу, чтобы увеличились продажи
- Извлекают информацию о посетителях веб-сайтов из журналов веб-сервера
- Анализируют биологические данные
- Отслеживают системные журналы для обнаружения злоумышленников
- Определяют чаще ли покупатели чая берут газированные напитки
Анализ дерева классификации
Новости по теме
Платформа DeFi Cred расследует мошенничество с…
28 Окт, 2020
Grayscale Investments: более половины инвесторов в США…
28 Окт, 2020
Хакеры взломали сайт Трампа и разместили кошельки для сбора…
28 Окт, 2020
Статистическая классификация определяет категории, к которым относится новое наблюдение.
Статистическая классификация используется для:
- Автоматического присвоения документов категориям
- Классификации организмов по группам
- Разработки профилей студентов, проходящих онлайн-курсы
Генетические алгоритмы
Генетические алгоритмы вдохновлены тем, как работает эволюция, то есть с помощью таких механизмов, как наследование, мутация и естественный отбор.
Генетические алгоритмы используют для:
- Составления расписания врачей для отделений неотложной помощи в больницах
- Расчет оптимальных материалов для разработки экономичных автомобилей
- Создания «искусственно творческого» контента, такого как игра слов и шутки
Регрессионный анализ
Как возраст человека влияет на тип автомобиля, который он покупает?
На базовом уровне регрессионный анализ включает в себя манипулирование некоторой независимой переменной (например, фоновой музыкой) чтобы увидеть, как она влияет на зависимую переменную (время, проведенное в магазине).
Регрессионный анализ используют для определения:
- Уровней удовлетворенности клиентов
- Как прогноз погоды за предыдущий день влияет на количество полученных звонков в службу поддержки
- Как район и размер домов влияют на цену жилья
Data Mining — как собирается и обрабатывается Биг Дата
Загрузка больших данных в традиционную реляционную базу для анализа занимает много времени и денег. По этой причине появились специальные подходы для сбора и анализа информации. Для получения и последующего извлечения информацию объединяют и помещают в «озеро данных”. Оттуда программы искусственного интеллекта, используя сложные алгоритмы, ищут повторяющиеся паттерны.
Хранение и обработка происходит следующими инструментами:
- Apache HADOOP — пакетно-ориентированная система обработки данных. Система хранит и отслеживает информацию на нескольких машинах и масштабируется до нескольких тысяч серверов.
- HPPC — платформа с открытым исходным кодом, разработанная LexisNexis Risk Solutions. HPPC известна как суперкомпьютер Data Analytics (DAS), поддерживающая обработку данных как в пакетном режиме, так и в режиме реального времени. Система использует суперкомпьютеры и кластеры из обычных компьютеров.
- Storm — обрабатывает информацию в реальном времени. Использует Eclipse Public License с открытым исходным кодом.
Реальное применение Big Data
Самый быстрый рост расходов на технологии больших данных происходит в банковской сфере, здравоохранении, страховании, ценных бумагах и инвестиционных услугах, а также в области телекоммуникаций. Три из этих отраслей относятся к финансовому сектору, который имеет множество полезных вариантов для анализа Big Data: обнаружение мошенничества, управление рисками и оптимизация обслуживания клиентов.
Банки и компании, выпускающие кредитные карты, используют большие данные, чтобы выявлять закономерности, которые указывают на преступную деятельность. Из-за чего некоторые аналитики считают, что большие данные могут принести пользу криптовалюте. Алгоритмы смогут выявить мошенничество и незаконную деятельность в крипто-индустрии.
Благодаря криптовалюте такой как Биткойн и Эфириум блокчейн может фактически поддерживать любой тип оцифрованной информации. Его можно использовать в области Big Data, особенно для повышения безопасности или качества информации.
Например, больница может использовать его для обеспечения безопасности, актуальности данных пациента и полного сохранения их качества. Размещая базы данных о здоровьи в блокчейн, больница обеспечивает всем своим сотрудникам доступ к единому, неизменяемому источнику информации.
Также, как люди связывают криптовалюту с волатильностью, они часто связывают большие данные со способностью просеивать большие объемы информации. Big Data поможет отслеживать тенденции. На цену влияет множество факторов и алгоритмы больших данных учтут это, а затем предоставят решение.
Перспективы использования Биг Дата
Blockchain и Big Data — две развивающиеся и взаимодополняющие друг друга технологии. С 2016 блокчейн часто обсуждается в СМИ. Это криптографически безопасная технология распределенных баз данных для хранения и передачи информации. Защита частной и конфиденциальной информации — актуальная и будущая проблема больших данных, которую способен решить блокчейн.
Почти каждая отрасль начала инвестировать в аналитику Big Data, но некоторые инвестируют больше, чем другие. По информации IDC, больше тратят на банковские услуги, дискретное производство, процессное производство и профессиональные услуги. По исследованиям Wikibon, выручка от продаж программ и услуг на мировом рынке в 2018 году составила $42 млрд, а в 2027 году преодолеет отметку в $100 млрд.
По оценкам Neimeth, блокчейн составит до 20% общего рынка больших данных к 2030 году, принося до $100 млрд. годового дохода. Это превосходит прибыль PayPal, Visa и Mastercard вместе взятые.
Аналитика Big Data будет важна для отслеживания транзакций и позволит компаниям, использующим блокчейн, выявлять скрытые схемы и выяснять с кем они взаимодействуют в блокчейне.
Рынок Big data в России
Весь мир и в том числе Россия используют технологию Big Data в банковской сфере, услугах связи и розничной торговле. Эксперты считают, что в будущем технологию будут использовать транспортная отрасль, нефтегазовая и пищевая промышленность, а также энергетика.
Аналитики IDC признали Россию крупнейшим региональным рынком BDA. По расчетам в текущем году выручка приблизится к 1,4 миллиардам долларов и будет составлять 40% общего объема инвестиций в секторе больших данных и приложений бизнес-аналитики.
Big Data
Как употреблять
С точки зрения транскрипции правильно говорить «биг дэйта», но если вы скажете «биг дата», криминала не будет — такой вариант произношения уже прижился, и, не исключено, именно он однажды войдёт в словари как нормативный вариант.
Почему data, а не datas, ведь «данные» — их много? Отвечаем: слово data является заимствованием из латинского языка, где множественное и единственное число образуются не так, как в английском, и data — это как раз форма множественного числа от datum. В общем, говорить «дата» можно, а «датас/дэйтас» нет. Русский эквивалент — «большие данные» — тоже уверенно вошёл в оборот, хоть он и в два раза длиннее.
«Большие данные — это когда больше терабайта», «большие данные — это объём информации, который невозможно обработать на одном компьютере», «большие данные — это новая нефть». Сколько людей, столько и определений big data. Формальной дефиниции не существует: неясно, где проходит граница между большими и просто данными.
Изначально понятие big data описывалось через три V: объём (volume) — очень много информации; скорость (velocity) — данные быстро увеличиваются и обрабатываются; многообразие (variety) — в работу идут и числа, и тексты, и графические образы, и другие виды данных, в том числе неструктурированных.
Потом количество V увеличилось: аналитики предложили добавить veracity — достоверность; viability — жизнеспособность; value — ценность для экономики, науки и общества; variability — переменчивость; visualization — возможность образного представления.
Ясно одно: речь идёт не просто о горах данных, которыми зачем-то забивают сервера научные лаборатории и коммерческие компании. Люди стремятся не только накапливать терабайты информации, но и извлекать из них пользу. Поэтому big data — это не столько про объём, сколько про подходы, инструменты, методы обработки данных, которые помогают добыть из тонн цифровой «руды» грамм «золота». Например, в квинтиллионах информации, собираемой телескопами NASA, найти следы новой планеты.

Data science
Чаще всего используется английская версия — «дата сайнс» или «дэйта сайнс». Русский аналог — «наука о данных».
Это наука о методах анализа данных и извлечения из них ценной информации. Data science как академическая дисциплина формируется с начала 2010-х. Чтобы стать специалистом в этой области, необходимо прежде всего быть отличным математиком — знать матмоделирование, матстатистику, комбинаторику, теорию графов и многое другое. Ну и, конечно, уметь программировать. Надо заметить, пока спрос на дата-сайентистов сильно превышает предложение (особенно в России).

Машинное обучение
Русское словосочетание «машинное обучение» используется так же часто, как английское machine learning (что-то вроде «мэшин лёрнинг»).
«Именно благодаря машинному обучению поисковая машина понимает, какие результаты (и рекламу) показывать в ответ на ваш запрос. Когда вы просматриваете почту, большая часть спама проходит мимо вас, потому что он был отфильтрован с помощью машинного обучения. Если вы решили что-нибудь купить на Amazon.com или заглянули на Netflix в поисках фильма, система машинного обучения услужливо предложит варианты, которые могут прийтись вам по вкусу. С помощью машинного обучения Facebook решает, какие новости вам показывать, а Twitter подбирает подходящие твиты» — с этих слов начинается книга «Верховный алгоритм» исследователя искусственного интеллекта Педро Домингоса.

Data mining
Data mining переводится с английского как «обнаружение знаний в базах данных», что отражает суть понятия, но звучит уж слишком длинно. Поэтому принято говорить «дата/дэйта майнинг», «майнить» — извлекать данные, «намайнить» — извлечь.
Датамайнингом называют как технологии, так и процесс обнаружения в сырых данных неизвестной и полезной информации. Основу data mining составляют всевозможные методы классификации, моделирования и прогнозирования.
В научный обиход термин ввёл израильский математик Григорий Пятецкий-Шапиро — ещё в 1989 году.

Облака
Говорят как «облако»/»облачный», так и cloud (например, cloud computing — облачные вычисления).
Держать в голове все задачи на день, месяц, год не очень-то удобно, поэтому мы записываем их в блокнот или заносим на виртуальную доску. Точно так же наш компьютер не может хранить на своём диске сотни гигабайт видео, фоток и музыки — их приходится закачивать на такие сервисы, как Google Drive или Яндекс.Диск.
Мы имеем постоянный доступ к своим данным — через интернет, но физически они находятся на виртуальных серверах соответствующих компаний. При этом пользователь платит лишь за место в хранилище, а это гораздо дешевле аренды целого сервера. Естественно, для работы с большими данными «облака» просто необходимы.

Суперкомпьютер
Не раздумывая и не сомневаясь. Это слово начало входить в русский язык ещё в конце 1960-х, когда в СССР появился первый суперкомпьютер БЭСМ‑6, способный выполнять 1 млн операций в секунду.
Речь идёт о вычислительной машине, значительно превосходящей по техническим параметрам и скорости обработки данных обычные персоналки. Как правило, она представляет собой систему высокопроизводительных компьютеров. Используется для решения задач в самых разных областях науки и технологий: от разработки атомного оружия до моделирования новых лекарств. Самые мощные российские суперкомпьютеры — «Ломоносов» и «Ломоносов‑2» — находятся в Московском государственном университете им. М. В. Ломоносова.

Интернет вещей
Популярен и русский вариант, и английский — internet of things, а также аббревиатура IoT.
Вслед за компьютерами и смартфонами в Сеть вышли фитнес-трекеры, чайники, стиральные машины, телевизоры, датчики и сенсоры. И всё же интернет вещей — это не включение света посредством брюк или удалённый спуск воды в унитазе через смартфон. Есть масса примеров внедрения технологий IoT в медицине, спорте, сельском хозяйстве, промышленности. Например, BigBelly — урна, которая предупреждает сотрудников городской службы по уборке мусора, что её пора опорожнить. Локальная сеть анализирует данные, полученные от каждой урны, что позволяет планировать частоту вывоза бытовых отходов.
В 1990 году выпускник Массачусетского технологического института, один из отцов протокола TCP/IP Джон Ромки создал первую в мире интернет-вещь. Он подключил к Сети свой тостер. Термин «интернет вещей» появился в 1999 году. Ожидается, что в 2020‑м IoT объединит более 30 млрд устройств.
Определение Big data обычно расшифровывают довольно просто – это огромный объем информации, часто бессистемной, которая хранится на каком либо цифровом носителе. Однако массив данных с приставкой «Биг» настолько велик, что привычными средствами структурирования и аналитики «перелопатить» его невозможно. Поэтому под термином «биг дата» понимают ещё и технологии поиска, обработки и применения неструктурированной информации в больших объемах.
Экскурс в историю и статистику
Словосочетание «большие данные» появилось в 2008 году с легкой руки Клиффорда Линча. В спецвыпуске журнала Nature эксперт назвал взрывной рост потоков информации — big data. В него он отнес любые массивы неоднородных данных свыше 150 Гб в сутки.
Из статистических выкладок аналитических агентств в 2005 году мир оперировал 4-5 эксабайтами информации (4-5 миллиардов гигабайтов), через 5 лет объемы big data выросли до 0,19 зеттабайт (1 ЗБ = 1024 ЭБ). В 2012 году показатели возросли до 1,8 ЗБ, а в 2015 – до 7 ЗБ. Эксперты прогнозируют, что к 2020 году системы больших данных будут оперировать 42-45 зеттабайтов информации. 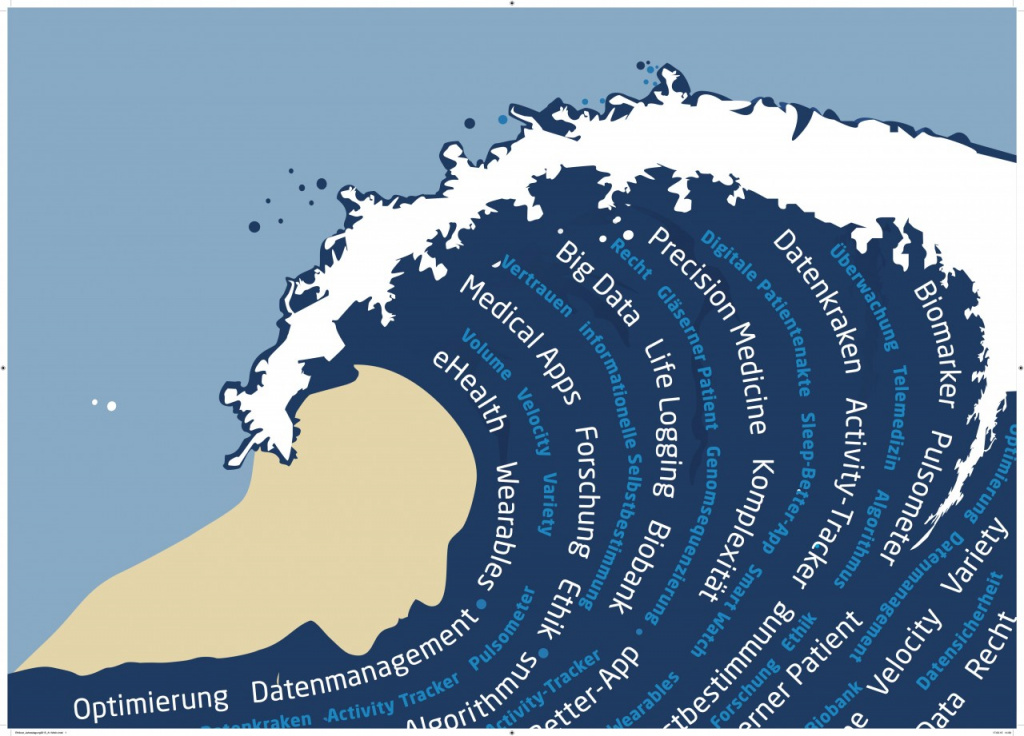
До 2011 года технологии больших данных рассматривались только в качестве научного анализа и практического выхода ни имели. Однако объемы данных росли по экспоненте и проблема огромных массивов неструктурированной и неоднородной информации стала актуальной уже в начале 2012 году. Всплеск интереса к big data хорошо виден в Google Trends.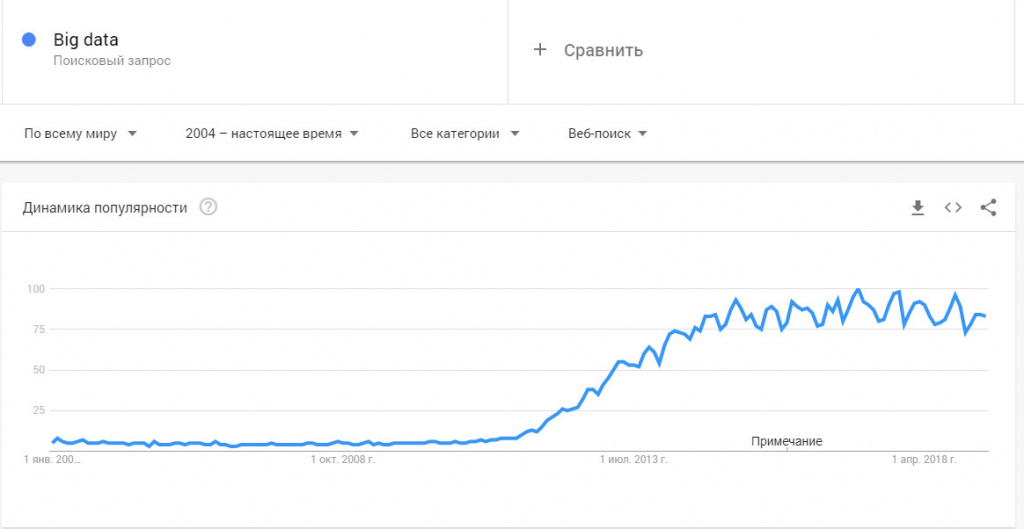
К развитию нового направления подключились мастодонты цифрового бизнеса – Microsoft, IBM, Oracle, EMC и другие. С 2014 года большие данные изучают в университетах, внедряют в прикладные науки – инженерию, физику, социологию.
Как работает технология big data?
Чтобы массив информации обозначить приставкой «биг» он должен обладать следующими признаками: 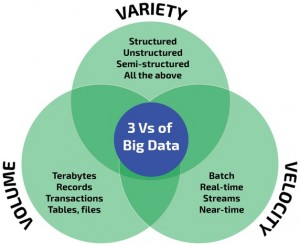
Правило VVV:
- Объем (Volume) – данные измеряются по физической величине и занимаемому пространству на цифровом носителе. К «биг» относят массивы свыше 150 Гб в сутки.
- Скорость, обновление (Velocity) – информация регулярно обновляется и для обработки в реальном времени необходимы интеллектуальные технологии больших данных.
- Разнообразие (Variety) – информация в массивах может иметь неоднородные форматы, быть структурированной частично, полностью и скапливаться бессистемно. Например, социальные сети используют большие данные в виде текстов, видео, аудио, финансовых транзакций, картинок и прочего.
В современных системах рассматриваются два дополнительных фактора:
- Изменчивость (Variability) – потоки данных могут иметь пики и спады, сезонности, периодичность. Всплески неструктурированной информации сложны в управлении, требует мощных технологий обработки.
- Значение данных (Value) – информация может иметь разную сложность для восприятия и переработки, что затрудняет работу интеллектуальным системам. Например, массив сообщений из соцсетей – это один уровень данных, а транзакционные операции – другой. Задача машин определить степень важности поступающей информации, чтобы быстро структурировать.
Принцип работы технологии big data основан на максимальном информировании пользователя о каком-либо предмете или явлении. Задача такого ознакомления с данными – помочь взвесить все «за» и «против», чтобы принять верное решение. В интеллектуальных машинах на основе массива информации строится модель будущего, а дальше имитируются различные варианты и отслеживаются результаты. 
Современные аналитические агентства запускают миллионы подобных симуляций, когда тестируют идею, предположение или решают проблему. Процесс автоматизирован.
К источникам big data относят:
- интернет – блоги, соцсети, сайты, СМИ и различные форумы;
- корпоративную информацию – архивы, транзакции, базы данных;
- показания считывающих устройств – метеорологические приборы, датчики сотовой связи и другие.
Принципы работы с массивами данных включают три основных фактора:
- Расширяемость системы. Под ней понимают обычно горизонтальную масштабируемость носителей информации. То есть выросли объемы входящих данных – увеличились мощность и количество серверов для их хранения.
- Устойчивость к отказу. Повышать количество цифровых носителей, интеллектуальных машин соразмерно объемам данных можно до бесконечности. Но это не означает, что часть машин не будет выходить из строя, устаревать. Поэтому одним из факторов стабильной работы с большими данными является отказоустойчивость серверов.
- Локализация. Отдельные массивы информации хранятся и обрабатываются в пределах одного выделенного сервера, чтобы экономить время, ресурсы, расходы на передачу данных.
Для чего используют?
Чем больше мы знаем о конкретном предмете или явлении, тем точнее постигаем суть и можем прогнозировать будущее. Снимая и обрабатывая потоки данных с датчиков, интернета, транзакционных операций, компании могут довольно точно предсказать спрос на продукцию, а службы чрезвычайных ситуаций предотвратить техногенные катастрофы. Приведем несколько примеров вне сферы бизнеса и маркетинга, как используются технологии больших данных:
- Здравоохранение. Больше знаний о болезнях, больше вариантов лечения, больше информации о лекарственных препаратах – всё это позволяет бороться с такими болезнями, которые 40-50 лет назад считались неизлечимыми.
- Предупреждение природных и техногенных катастроф. Максимально точный прогноз в этой сфере спасает тысячи жизней людей. Задача интеллектуальных машин собрать и обработать множество показаний датчиков и на их основе помочь людям определить дату и место возможного катаклизма.
- Правоохранительные органы. Большие данные используются для прогнозирования всплеска криминала в разных странах и принятия сдерживающих мер, там, где этого требует ситуация.
Методики анализа и обработки

К основным способам анализа больших массивов информации относят следующие:
- Глубинный анализ, классификация данных. Эти методики пришли из технологий работы с обычной структурированной информацией в небольших массивах. Однако в новых условиях используются усовершенствованные математические алгоритмы, основанные на достижениях в цифровой сфере.
- Краудсорсинг. В основе этой технологии возможность получать и обрабатывать потоки в миллиарды байт из множества источников. Конечное число «поставщиков» не ограничивается ничем. Разве только мощностью системы.
- Сплит-тестирование. Из массива выбираются несколько элементов, которые сравниваются между собой поочередно «до» и «после» изменения. А\В тесты помогают определить, какие факторы оказывают наибольшее влияние на элементы. Например, с помощью сплит-тестирования можно провести огромное количество итераций постепенно приближаясь к достоверному результату.
- Прогнозирование. Аналитики стараются заранее задать системе те или иные параметры и в дальнейшей проверять поведение объекта на основе поступления больших массивов информации.
- Машинное обучение. Искусственный интеллект в перспективе способен поглощать и обрабатывать большие объемы несистематизированных данных, впоследствии используя их для самостоятельного обучения.
- Анализ сетевой активности. Методики big data используются для исследования соцсетей, взаимоотношений между владельцами аккаунтов, групп, сообществами. На основе этого создаются целевые аудитории по интересам, геолокации, возрасту и прочим метрикам.
Большие данные в бизнесе и маркетинге
Стратегии развития бизнеса, маркетинговые мероприятия, реклама основаны на анализе и работе с имеющимися данными. Большие массивы позволяют «перелопатить» гигантские объемы данных и соответственно максимально точно скорректировать направление развития бренда, продукта, услуги.
Например, аукцион RTB в контекстной рекламе работают с big data, что позволяет эффективно рекламировать коммерческие предложения выделенной целевой аудитории, а не всем подряд.
Какие выгоды для бизнеса:
- Создание проектов, которые с высокой вероятностью станут востребованными у пользователей, покупателей.
- Изучение и анализ требований клиентов с существующим сервисом компании. На основе выкладки корректируется работа обслуживающего персонала.
- Выявление лояльности и неудовлетворенности клиентской базы за счет анализа разнообразной информации из блогов, соцсетей и других источников.
- Привлечение и удержание целевой аудитории благодаря аналитической работе с большими массивами информации.
Технологии используют в прогнозировании популярности продуктов, например, с помощью сервиса Google Trends и Яндекс. Вордстат (для России и СНГ). 
Методики big data используют все крупные компании – IBM, Google, Facebook и финансовые корпорации – VISA, Master Card, а также министерства разных стран мира. Например, в Германии сократили выдачу пособий по безработице, высчитав, что часть граждан получают их без оснований. Так удалось вернуть в бюджет около 15 млрд. евро.
Недавний скандал с Facebook из-за утечки данных пользователей говорит о том, что объемы неструктурированной информации растут и даже мастодонты цифровой эры не всегда могут обеспечить их полную конфиденциальность. 
Например, Master Card используют большие данные для предотвращения мошеннических операций со счетами клиентов. Так удается ежегодно спасти от кражи более 3 млрд. долларов США.
В игровой сфере big data позволяет проанализировать поведение игроков, выявить предпочтения активной аудитории и на основе этого прогнозировать уровень интереса к игре.
Сегодня бизнес знает о своих клиентах больше, чем мы сами знаем о себе – поэтому рекламные кампании Coca-Cola и других корпораций имеют оглушительный успех.
Перспективы развития
В 2019 году важность понимания и главное работы с массивами информации возросла в 4-5 раз по сравнению с началом десятилетия. С массовостью пришла интеграция big data в сферы малого и среднего бизнеса, стартапы:
- Облачные хранилища. Технологии хранения и работы с данными в онлайн-пространстве позволяет решить массу проблем малого и среднего бизнеса: дешевле купить облако, чем содержать дата-центр, персонал может работать удаленно, не нужен офис.
- Глубокое обучение, искусственный интеллект. Аналитические машины имитируют человеческий мозг, то есть используются искусственные нейронные сети. Обучение происходит самостоятельно на основе больших массивов информации.
- Dark Data – сбор и хранение не оцифрованных данных о компании, которые не имеют значимой роли для развития бизнеса, однако они нужны в техническом и законодательном планах.
- Блокчейн. Упрощение интернет-транзакций, снижение затрат на проведение этих операций.
- Системы самообслуживания – с 2016 года внедряются специальные платформы для малого и среднего бизнеса, где можно самостоятельно хранить и систематизировать данные.
Резюме
Мы изучили, что такое big data? Рассмотрели, как работает эта технология, для чего используются массивы информации. Познакомились с принципами и методиками работы с большими данными.
Рекомендуем к прочтению книгу Рика Смолана и Дженнифер Эрвитт «The Human Face of Big Data», а также труд «Introduction to Data Mining» Майкла Стейнбаха, Випин Кумар и Панг-Нинг Тан.
Что такое Big Data (дословно — большие данные)? Обратимся сначала к оксфордскому словарю:
Данные — величины, знаки или символы, которыми оперирует компьютер и которые могут храниться и передаваться в форме электрических сигналов, записываться на магнитные, оптические или механические носители.
Термин Big Data используется для описания большого и растущего экспоненциально со временем набора данных. Для обработки такого количества данных не обойтись без машинного обучения.
Преимущества, которые предоставляет Big Data:
- Сбор данных из разных источников.
- Улучшение бизнес-процессов через аналитику в реальном времени.
- Хранение огромного объема данных.
- Инсайты. Big Data более проницательна к скрытой информации при помощи структурированных и полуструктурированных данных.
- Большие данные помогают уменьшать риск и принимать умные решения благодаря подходящей риск-аналитике
Примеры Big Data
Нью-Йоркская Фондовая Биржа ежедневно генерирует 1 терабайт данных о торгах за прошедшую сессию.
Социальные медиа: статистика показывает, что в базы данных Facebook ежедневно загружается 500 терабайт новых данных, генерируются в основном из-за загрузок фото и видео на серверы социальной сети, обмена сообщениями, комментариями под постами и так далее.
Реактивный двигатель генерирует 10 терабайт данных каждые 30 минут во время полета. Так как ежедневно совершаются тысячи перелетов, то объем данных достигает петабайты.
Классификация Big Data
Формы больших данных:
- Структурированная
- Неструктурированная
- Полуструктурированная
Структурированная форма
Данные, которые могут храниться, быть доступными и обработанными в форме с фиксированным форматом называются структурированными. За продолжительное время компьютерные науки достигли больших успехов в совершенствовании техник для работы с этим типом данных (где формат известен заранее) и научились извлекать пользу. Однако уже сегодня наблюдаются проблемы, связанные с ростом объемов до размеров, измеряемых в диапазоне нескольких зеттабайтов.
1 зеттабайт соответствует миллиарду терабайт
Глядя на эти числа, нетрудно убедиться в правдивости термина Big Data и трудностях сопряженных с обработкой и хранением таких данных.
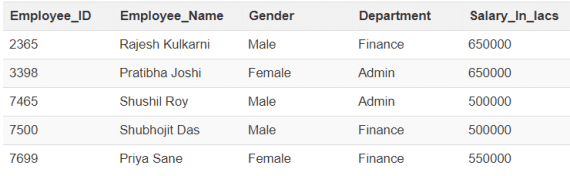
Данные, хранящиеся в реляционной базе — структурированы и имеют вид ,например, таблицы сотрудников компании
Неструктурированная форма
Данные неизвестной структуры классифицируются как неструктурированные. В дополнении к большим размерам, такая форма характеризуется рядом сложностей для обработки и извлечении полезной информации. Типичный пример неструктурированных данных — гетерогенный источник, содержащий комбинацию простых текстовых файлов, картинок и видео. Сегодня организации имеют доступ к большому объему сырых или неструктурированных данных, но не знают как извлечь из них пользу.
Примером такой категории Big Data является результат Гугл поиска:
Полуструктурированная форма
Эта категория содержит обе описанные выше, поэтому полуструктурированные данные обладают некоторой формой, но в действительности не определяются с помощью таблиц в реляционных базах. Пример этой категории — персональные данные, представленные в XML файле.
<rec><name>Prashant Rao</name><sex>Male</sex><age>35</age></rec> <rec><name>Seema R.</name><sex>Female</sex><age>41</age></rec> <rec><name>Satish Mane</name><sex>Male</sex><age>29</age></rec> <rec><name>Subrato Roy</name><sex>Male</sex><age>26</age></rec> <rec><name>Jeremiah J.</name><sex>Male</sex><age>35</age></rec>
Характеристики Big Data
Рост Big Data со временем:
Синим цветом представлены структурированные данные (Enterprise data), которые сохраняются в реляционных базах. Другими цветами — неструктурированные данные из разных источников (IP-телефония, девайсы и сенсоры, социальные сети и веб-приложения).
В соответствии с Gartner, большие данные различаются по объему, скорости генерации, разнообразию и изменчивости. Рассмотрим эти характеристики подробнее.
- Объем. Сам по себе термин Big Data связан с большим размером. Размер данных — важнейший показатель при определении возможной извлекаемой ценности. Ежедневно 6 миллионов людей используют цифровые медиа, что по предварительным оценкам генерирует 2.5 квинтиллиона байт данных. Поэтому объем — первая для рассмотрения характеристика.
- Разнообразие — следующий аспект. Он ссылается на гетерогенные источники и природу данных, которые могут быть как структурированными, так и неструктурированными. Раньше электронные таблицы и базы данных были единственными источниками информации, рассматриваемыми в большинстве приложений. Сегодня же данные в форме электронных писем, фото, видео, PDF файлов, аудио тоже рассматриваются в аналитических приложениях. Такое разнообразие неструктурированных данных приводит к проблемам в хранении, добыче и анализе: 27% компаний не уверены, что работают с подходящими данными.
- Скорость генерации. То, насколько быстро данные накапливаются и обрабатываются для удовлетворения требований, определяет потенциал. Скорость определяет быстроту притока информации из источников — бизнес процессов, логов приложений, сайтов социальных сетей и медиа, сенсоров, мобильных устройств. Поток данных огромен и непрерывен во времени.
- Изменчивость описывает непостоянство данных в некоторые моменты времени, которое усложняет обработку и управление. Так, например, большая часть данных неструктурирована по своей природе.
Big Data аналитика: в чем польза больших данных
Продвижение товаров и услуг: доступ к данным из поисковиков и сайтов, таких как Facebook и Twitter, позволяет предприятиям точнее разрабатывать маркетинговые стратегии.
Улучшение сервиса для покупателей: традиционные системы обратной связи с покупателями заменяются на новые, в которых Big Data и обработка естественного языка применяется для чтения и оценки отзыва покупателя.
Расчет риска, связанного с выпуском нового продукта или услуги.
Операционная эффективность: большие данные структурируют, чтобы быстрее извлекать нужную информацию и оперативно выдавать точный результат. Такое объединение технологий Big Data и хранилищ помогает организациям оптимизировать работу с редко используемой информацией.
Технологии:
- NoSQL;
- MapReduce;
- Hadoop;
- R;
- Аппаратные решения.
Читайте также: Big data: семантический анализ данных и машинное обучение
Для больших данных выделяют традиционные определяющие характеристики, выработанные Meta Group ещё в 2001 году, которые называются «Три V»:
- Volume — величина физического объёма.
- Velocity — скорость прироста и необходимости быстрой обработки данных для получения результатов.
- Variety — возможность одновременно обрабатывать различные типы данных.
Big data: применение и возможности
Объёмы неоднородной и быстро поступающей цифровой информации обработать традиционными инструментами невозможно. Сам анализ данных позволяет увидеть определённые и незаметные закономерности, которые не может увидеть человек. Это позволяет оптимизировать все сферы нашей жизни — от государственного управления до производства и телекоммуникаций.
Например, некоторые компании ещё несколько лет назад защищали своих клиентов от мошенничества, а забота о деньгах клиента — забота о своих собственных деньгах.
Сюзан Этлиджер: Как быть с большими данными?
Решения на основе Big data: «Сбербанк», «Билайн» и другие компании
У «Билайна» есть огромное количество данных об абонентах, которые они используют не только для работы с ними, но и для создания аналитических продуктов, вроде внешнего консалтинга или IPTV-аналитики. «Билайн» сегментировали базу и защитили клиентов от денежных махинаций и вирусов, использовав для хранения HDFS и Apache Spark, а для обработки данных — Rapidminer и Python.
Читайте также: «Большие данные дают конкурентное преимущество, поэтому не все хотят о них рассказывать»
Или вспомним «Сбербанк» с их старым кейсом под названием АС САФИ. Это система, которая анализирует фотографии для идентификации клиентов банка и предотвращает мошенничество. Система была внедрена ещё в 2014 году, в основе системы — сравнение фотографий из базы, которые попадают туда с веб-камер на стойках благодаря компьютерному зрению. Основа системы — биометрическая платформа. Благодаря этому, случаи мошенничества уменьшились в 10 раз.
Big data в мире
По данным компании IBS, к 2003 году мир накопил 5 эксабайтов данных (1 ЭБ = 1 млрд гигабайтов). К 2008 году этот объем вырос до 0,18 зеттабайта (1 ЗБ = 1024 эксабайта), к 2011 году — до 1,76 зеттабайта, к 2013 году — до 4,4 зеттабайта. В мае 2015 года глобальное количество данных превысило 6,5 зеттабайта ().
К 2020 году, по прогнозам, человечество сформирует 40-44 зеттабайтов информации. А к 2025 году вырастет в 10 раз, говорится в докладе The Data Age 2025, который был подготовлен аналитиками компании IDC. В докладе отмечается, что большую часть данных генерировать будут сами предприятия, а не обычные потребители.
Аналитики исследования считают, что данные станут жизненно-важным активом, а безопасность — критически важным фундаментом в жизни. Также авторы работы уверены, что технология изменит экономический ландшафт, а обычный пользователь будет коммуницировать с подключёнными устройствами около 4800 раз в день.
В 2017 году мировой доход на рынке big data должен достигнуть $150,8 млрд, что на 12,4% больше, чем в прошлом году. В мировом масштабе российский рынок услуг и технологий big data ещё очень мал. В 2014 году американская компания IDC оценивала его в $340 млн. В России технологию используют в банковской сфере, энергетике, логистике, государственном секторе, телекоме и промышленности.
Читайте также: Как устроен рынок Big data в России
Что касается рынка данных, он в России только зарождается. Внутри экосистемы RTB поставщиками данных выступают владельцы программатик-платформ управления данными (DMP) и бирж данных (data exchange). Телеком-операторы в пилотном режиме делятся с банками потребительской информацией о потенциальных заёмщиках.
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. Следите за Big Data Conference в Telegram, на Facebook и «ВКонтакте».
Обычно большие данные поступают из трёх источников:
- Интернет (соцсети, форумы, блоги, СМИ и другие сайты);
- Корпоративные архивы документов;
- Показания датчиков, приборов и других устройств.
Big data в банках
Помимо системы, описанной выше, в стратегии «Сбербанка» на 2014-2018 гг. говорится о важности анализа супермассивов данных для качественного обслуживания клиентов, управления рисками и оптимизации затрат. Сейчас банк использует Big data для управления рисками, борьбы с мошенничеством, сегментации и оценки кредитоспособности клиентов, управления персоналом, прогнозирования очередей в отделениях, расчёта бонусов для сотрудников и других задач.
«ВТБ24» пользуется большими данными для сегментации и управления оттоком клиентов, формирования финансовой отчётности, анализа отзывов в соцсетях и на форумах. Для этого он применяет решения Teradata, SAS Visual Analytics и SAS Marketing Optimizer.
Читайте также: Кто делает Big data в России?
«Альфа-Банк» за большие данные взялся в 2013 году. Банк использует технологии для анализа соцсетей и поведения пользователей сайта, оценки кредитоспособности, прогнозирования оттока клиентов, персонализации контента и вторичных продаж. Для этого он работает с платформами хранения и обработки Oracle Exadata, Oracle Big data Appliance и фреймворком Hadoop.
«Тинькофф-банк» с помощью EMC Greenplum, SAS Visual Analytics и Hadoop управляет рисками, анализирует потребности потенциальных и существующих клиентов. Большие данные задействованы также в скоринге, маркетинге и продажах.
Big data в бизнесе
Для оптимизации расходов внедрил Big data и «Магнитогорский металлургический комбинат», который является крупным мировым производителем стали. В конце прошлого года они внедрили сервис под названием «Снайпер», который оптимизирует расход ферросплавов и других материалов при производстве. Сервис обрабатывает данные и выдаёт рекомендации для того, чтобы сэкономить деньги на производстве стали.
Читайте также: Как заставить большие данные работать на ваш бизнес
Большие данные и будущее — одна из самых острых тем для обсуждения, ведь в основе коммерческой деятельности лежит информация. Идея заключается в том, чтобы «скормить» компьютеру большой объем данных и заставить его отыскивать типовые алгоритмы, которые не способен увидеть человек, или принимать решения на основе процента вероятности в том масштабе, с которым прекрасно справляется человек, но который до сих пор не был доступен для машин, или, возможно, однажды — в таком масштабе, с которым человек не справится никогда.
Читайте также: 6 современных тенденций в финансовом секторе
Чтобы оптимизировать бизнес-процессы,»Сургутнефтегаз» воспользовался платформой данных и приложений «in-memory» под названием SAP HANA, которая помогает в ведении бизнеса в реальном времени. Платформа автоматизирует учёт продукции, расчёт цен, обеспечивает сотрудников информацией и экономит аппаратные ресурсы. Как большие данные перевернули бизнес других предприятий — вы можете прочитать
Big data в маркетинге
Благодаря Big data маркетологи получили отличный инструмент, который не только помогает в работе, но и прогнозирует результаты. Например, с помощью анализа данных можно вывести рекламу только заинтересованной в продукте аудитории, основываясь на модели RTB-аукциона.
Читайте также: Чем полезны большие данные для рекламного бизнеса?
Big data позволяет маркетологам узнать своих потребителей и привлекать новую целевую аудиторию, оценить удовлетворённость клиентов, применять новые способы увеличения лояльности клиентов и реализовывать проекты, которые будут пользоваться спросом.
Сервис Google.Trends вам в помощь, если нужен прогноз сезонной активности спроса. Всё, что надо — сопоставить сведения с данными сайта и составить план распределения рекламного бюджета.
Читайте также: Большие данные должны приносить практическую пользу бизнесу – или умереть
Биг дата изменит мир?
От технологий нам не спрятаться, не скрыться. Big data уже меняет мир, потихоньку просачиваясь в наши города, дома, квартиры и гаджеты. Как быстро технология захватит планету — сказать сложно. Одно понятно точно — держись моды или умри в отстое, как говорил Боб Келсо в сериале «Клиника».